Retrieval Augmented Generation (RAG)
Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information. Implementing RAG in an LLM-based question answering system has two main benefits: It ensures that the model has access to the most current, reliable facts, and that users have access to the model’s sources, ensuring that its claims can be checked for accuracy and ultimately trusted.
RAG has additional benefits. By grounding an LLM on a set of external, verifiable facts, the model has fewer opportunities to pull information baked into its parameters. This reduces the chances that an LLM will leak sensitive data, or ‘hallucinate’ incorrect or misleading information.
RAG also reduces the need for users to continuously train the model on new data and update its parameters as circumstances evolve. In this way, RAG can lower the computational and financial costs of running LLM-powered chatbots in an enterprise setting.
How RAG work
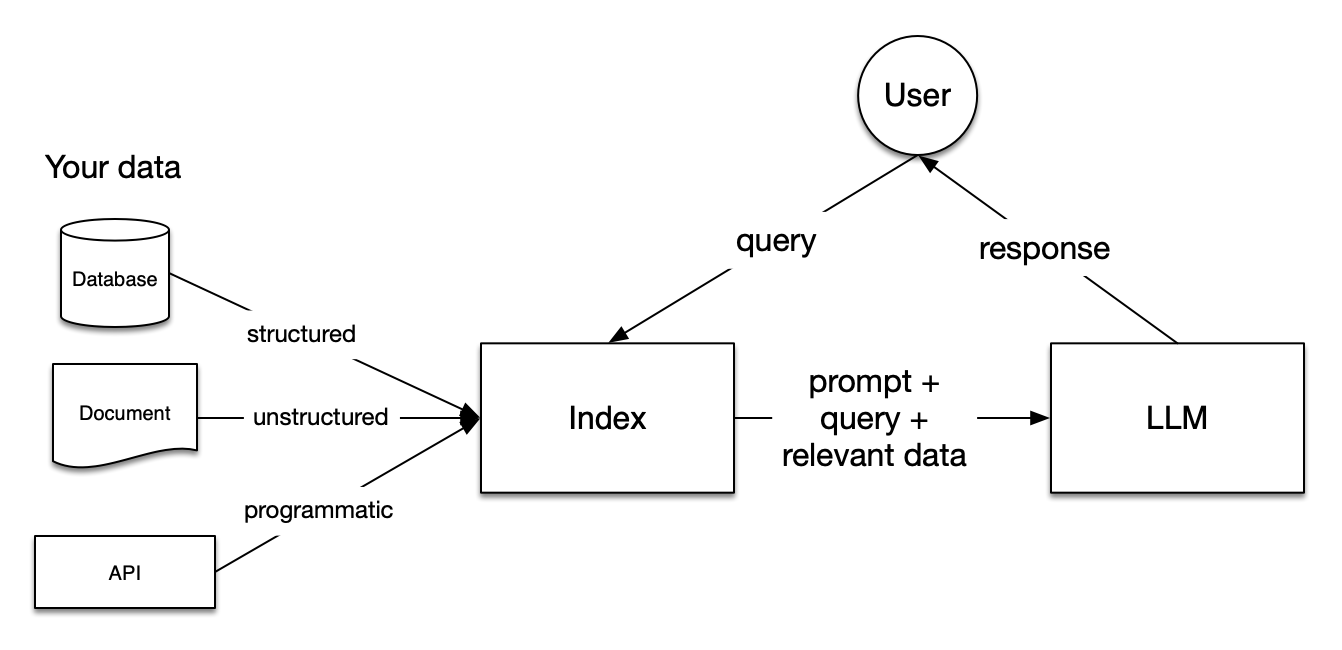
In RAG, your data is loaded and prepared for queries or “indexed”. User queries act on the index, which filters your data down to the most relevant context. This context and your query then go to the LLM along with a prompt, and the LLM provides a response.
Ingestion Stage - indexing

Source Data Preparation
The starting point of any RAG system is its source data, often consisting of a vast corpus of text documents, websites, or databases. This data serves as the knowledge reservoir that the retrieval model scans through to find relevant information.Data Loading: this refers to getting your data from where it lives – whether it’s text files, PDFs, another website, a database, or an API – into your pipeline.
Data Cleaning
It’s crucial to have diverse, accurate, and high-quality source data for optimal functioning. It is also important to manage and reduce redundancy in the source data.Data Chunking
Before the retrieval model can search through the data, it’s typically divided into manageable “chunks” or segments. This chunking process ensures that the system can efficiently scan through the data and enables quick retrieval of relevant content. Effective chunking strategies can drastically improve the model’s speed and accuracy: a document may be its own chunk, but it could also be split up into chapters/sections, paragraphs, sentences, or even just “chunks of words.” Remember: the goal is to be able to feed the Generative Model with information that will enhance its generation.Text-to-Vector Conversion (Embedding Models)
The next step involves converting the textual data into a format that the model can readily use. When using a vector database, this means transforming the text into mathematical vectors via a process known as “embedding”. These are almost always generated using complex software models that have been built with machine learning techniques. These vectors encapsulate the semantics and context of the text, making it easier for the retrieval model to identify relevant data points. Many embedding models can be fine-tuned to create good semantic matching; general-purpose embedding models such as GPT and LLaMa may not perform as well against scientific information as a model like SciBERT, for example.Vector Storing (Vector Database)
Once your data is indexed you will almost always want to store your index, as well as other metadata, to avoid having to re-index it. A vector database is designed to store, manage and index massive quantities of high-dimensional vector data efficiently. Unlike traditional relational databases with rows and columns, data points in a vector database are represented by vectors with a fixed number of dimensions, clustered based on similarity. This design enables low latency queries, making them ideal for AI-driven applications.
Inferencing Stage - Retrieval & Generation
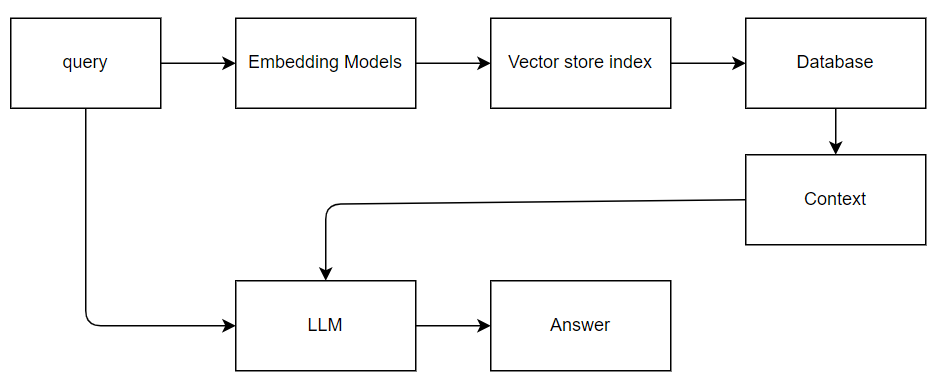
In a RAG pattern, queries and responses are coordinated between the search engine and the LLM. A user’s question or query is forwarded to both the search engine and to the LLM as a prompt. The search results come back from the search engine and are redirected to an LLM. The response that makes it back to the user is generative AI, either a summation or answer from the LLM.
Retrieve Models (should use the same model during embedding)
Retrieval models act as the information gatekeepers in the RAG architecture. Their primary function is to search through a large corpus of data to find relevant pieces of information that can be used for text generation. Think of them as specialized librarians who know exactly which ‘books’ to pull off the ‘shelves’ when you ask a question. These models use algorithms to rank and select the most pertinent data, offering a way to introduce external knowledge into the text generation process. By doing so, retrieval models set the stage for more informed, context-rich language generation, elevating the capabilities of traditional language models.Generate Models
Once the retrieval model has sourced the appropriate information, generative models come into play. These models act as creative writers, synthesizing the retrieved information into coherent and contextually relevant text. Usually built upon Large Language Models (LLMs), generative models can create text that is grammatically correct, semantically meaningful, and aligned with the initial query or prompt. They take the raw data selected by the retrieval models and give it a narrative structure, making the information easily digestible and actionable. In the RAG framework, generative models serve as the final piece of the puzzle, providing the textual output we interact with.
The Format of the prompt could be like:
1 | def question_answering(context, query): |
Frameworks with RAG
LlamaIndex
LlamaIndex is a data framework for LLM-based applications which benefit from context augmentation. Such LLM systems have been termed as RAG systems, standing for “Retrieval-Augemented Generation”.
LlamaIndex provides the essential abstractions to more easily ingest, structure, and access private or domain-specific data in order to inject these safely and reliably into LLMs for more accurate text generation.
LlamaIndex provides the following tools to help you quickly standup production-ready RAG systems:
Data connectors ingest your existing data from their native source and format. These could be APIs, PDFs, SQL, and (much) more.
Data indexes structure your data in intermediate representations that are easy and performant for LLMs to consume.
Engines provide natural language access to your data. For example:
Query engines are powerful retrieval interfaces for knowledge-augmented output.
Chat engines are conversational interfaces for multi-message, “back and forth” interactions with your data.
Data agents are LLM-powered knowledge workers augmented by tools, from simple helper functions to API integrations and more.
Application integrations tie LlamaIndex back into the rest of your ecosystem. This could be LangChain, Flask, Docker, ChatGPT, or… anything else!
LlamaIndex concepts
There are also some terms you’ll encounter that refer to steps within each of these stages.
Loading stage
Nodes and Documents: A Document is a container around any data source - for instance, a PDF, an API output, or retrieve data from a database. A Node is the atomic unit of data in LlamaIndex and represents a “chunk” of a source Document. Nodes have metadata that relate them to the document they are in and to other nodes.
Connectors: A data connector (often called a Reader) ingests data from different data sources and data formats into Documents and Nodes.
Indexing Stage
Indexes: Once you’ve ingested your data, LlamaIndex will help you index the data into a structure that’s easy to retrieve. This usually involves generating vector embeddings which are stored in a specialized database called a vector store. Indexes can also store a variety of metadata about your data.
Embeddings LLMs generate numerical representations of data called embeddings. When filtering your data for relevance, LlamaIndex will convert queries into embeddings, and your vector store will find data that is numerically similar to the embedding of your query.
Querying Stage
Retrievers: A retriever defines how to efficiently retrieve relevant context from an index when given a query. Your retrieval strategy is key to the relevancy of the data retrieved and the efficiency with which it’s done.
Routers: A router determines which retriever will be used to retrieve relevant context from the knowledge base. More specifically, the RouterRetriever class, is responsible for selecting one or multiple candidate retrievers to execute a query. They use a selector to choose the best option based on each candidate’s metadata and the query.
Node Postprocessors: A node postprocessor takes in a set of retrieved nodes and applies transformations, filtering, or re-ranking logic to them.
Response Synthesizers: A response synthesizer generates a response from an LLM, using a user query and a given set of retrieved text chunks.
Putting it all together
There are endless use cases for data-backed LLM applications but they can be roughly grouped into three categories:
Query Engines: A query engine is an end-to-end pipeline that allows you to ask questions over your data. It takes in a natural language query, and returns a response, along with reference context retrieved and passed to the LLM.
Chat Engines: A chat engine is an end-to-end pipeline for having a conversation with your data (multiple back-and-forth instead of a single question-and-answer).
Agents: An agent is an automated decision-maker powered by an LLM that interacts with the world via a set of tools. Agents can take an arbitrary number of steps to complete a given task, dynamically deciding on the best course of action rather than following pre-determined steps. This gives it additional flexibility to tackle more complex tasks.
LangChain
LangChain provides standard, extendable interfaces and external integrations:
Retrieval
Interface with application-specific data for e.g. RAGDocument loaders
Load data from a source as Documents for later processingText splitters
Transform source documents to better suit your applicationEmbedding models
Create vector representations of a piece of text, allowing for natural language searchVectorstores
Interfaces for specialized databases that can search over unstructured data with natural languageRetrievers
More generic interfaces that return documents given an unstructured query
more details, see:
https://python.langchain.com/docs/modules/
https://python.langchain.com/docs/use_cases/question_answering/quickstart/
reference
https://arxiv.org/pdf/2005.11401v4.pdf
https://research.ibm.com/blog/retrieval-augmented-generation-RAG
https://www.ibm.com/topics/vector-database
https://docs.llamaindex.ai/en/stable/getting_started/concepts/
https://docs.llamaindex.ai/en/stable/
https://www.datastax.com/guides/what-is-retrieval-augmented-generation
https://developer.nvidia.com/blog/rag-101-retrieval-augmented-generation-questions-answered/
https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview
https://python.langchain.com/docs/use_cases/question_answering/quickstart/
本文标题:Retrieval Augmented Generation (RAG)
文章作者:Mr Bluyee
发布时间:2024-04-07
最后更新:2024-04-07
原始链接:https://www.mrbluyee.com/2024/04/07/Retrieval-Augmented-Generation-RAG/
版权声明:The author owns the copyright, please indicate the source reproduced.