anything LLM with ollama - a private document chatbot
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
deploy with docker
Pull in the latest image from docker:
1 | docker pull mintplexlabs/anythingllm |
on linux:
1 | export STORAGE_LOCATION=$HOME/anythingllm && \ |
on windows:
1 | # Run this in powershell terminal |
To access the full application, visit http://localhost:3001 in your browser.
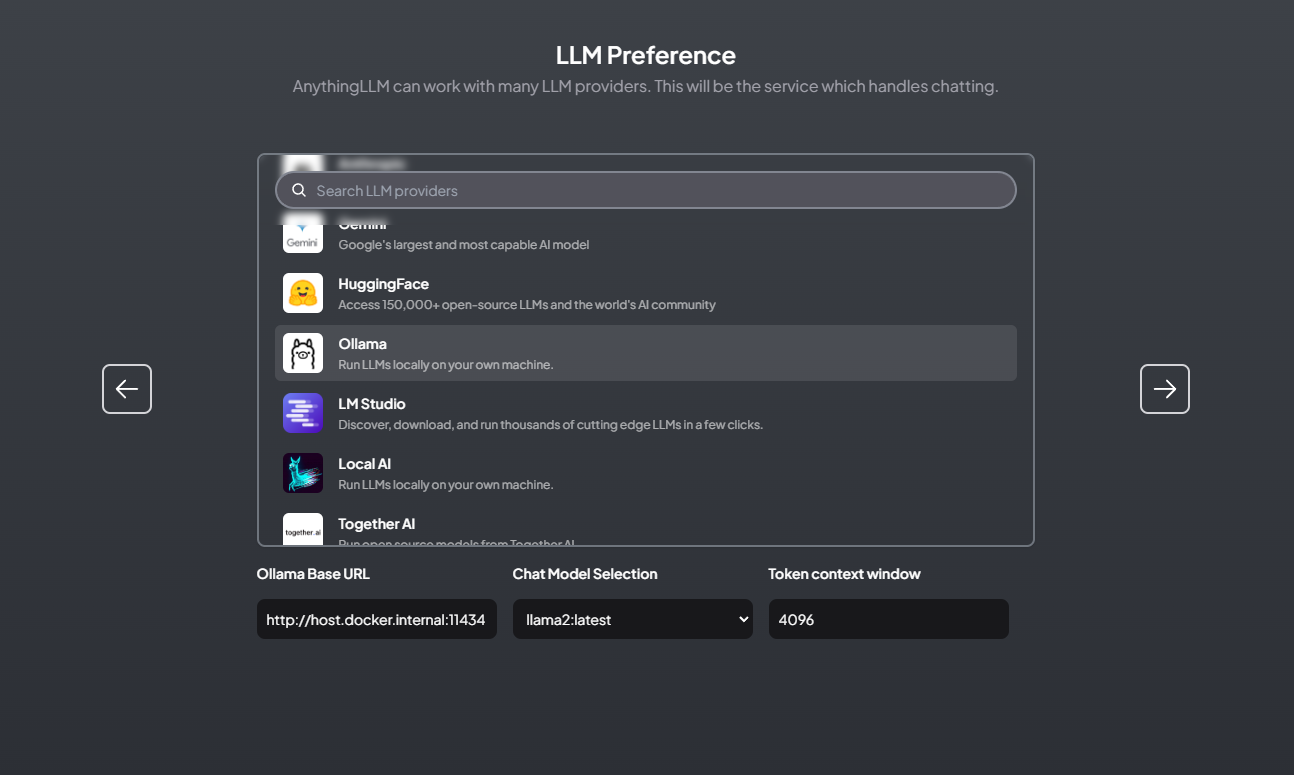
Base URL:
http://host.docker.internal:11434
Note:
On linux http://host.docker.internal:11434 does not work.
Use http://172.17.0.1:11434 instead to emulate this functionality.
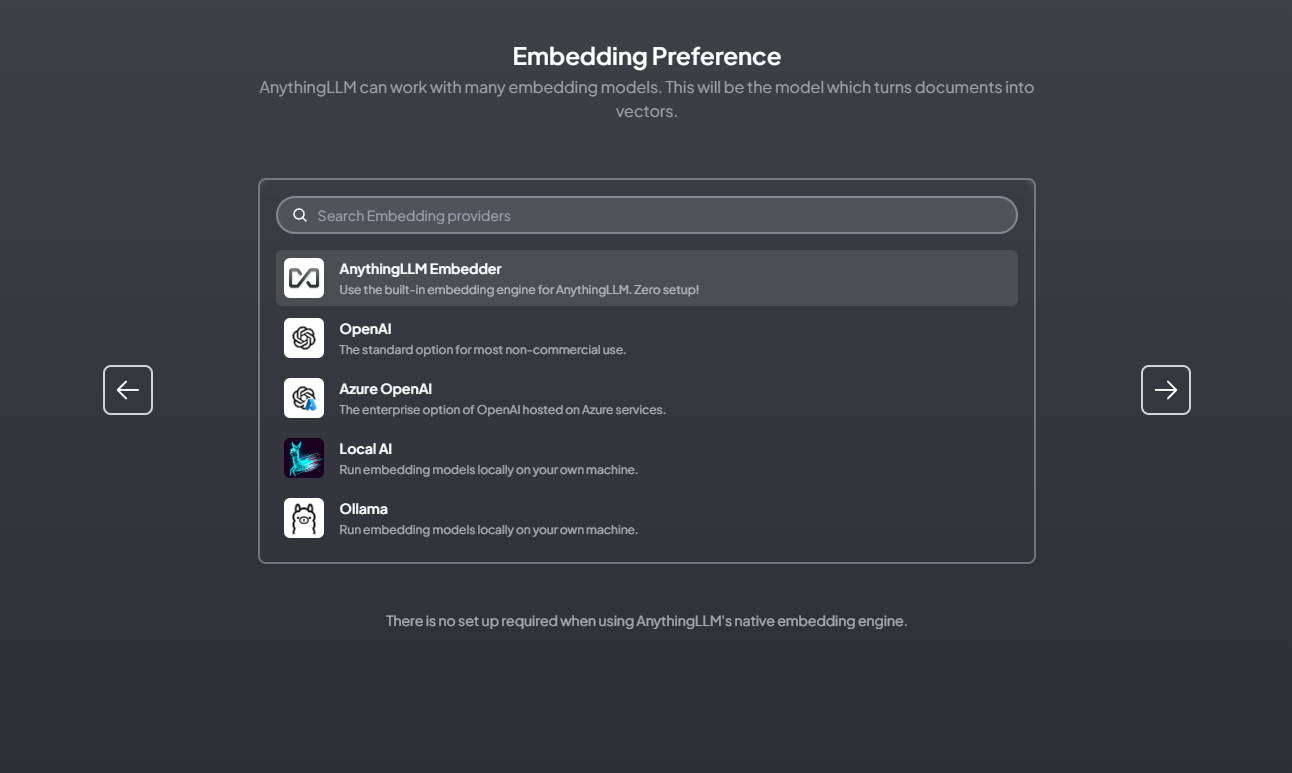
We could select the default one: AnythingLLM Native Embedder
It will use the ONNX all-MiniLM-L6-v2 model built by Xenova on HuggingFace.co.
This model is a quantized and WASM version of the popular all-MiniLM-L6-v2 which produces a 384-dimension vector.
For the text generation, it recommends at least using a 4-bit or 5-bit quantized model of the used LLM.
Lower quantization models tend to just output unreadable garbage. For more detailed info, please see:
https://github.com/Mintplex-Labs/anything-llm/blob/master/server/storage/models/README.md
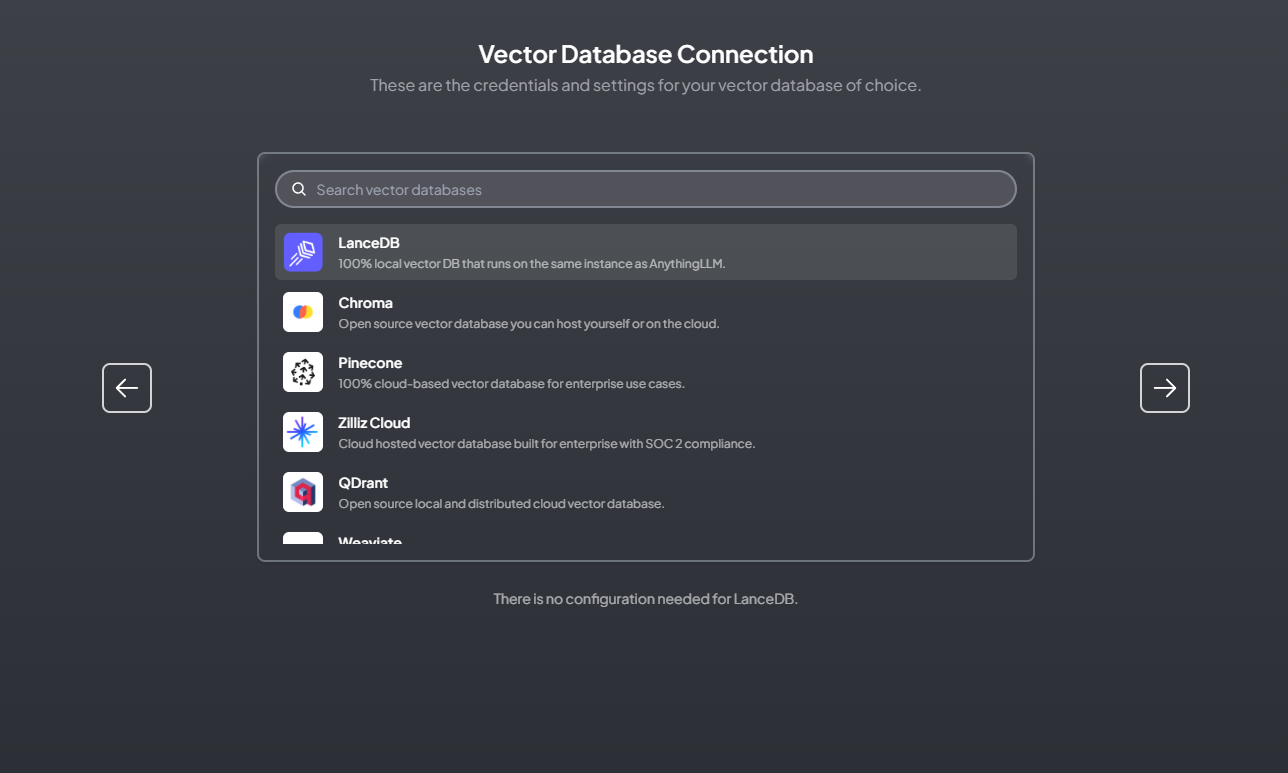
For the vector database, we could also select the default one: LanceDB
For more detailed info, please see: https://github.com/lancedb/lancedb
how does AnythingLLM work
A workspace is created. The LLM can only “see” documents embedded in this workspace. If a document is not embedded, there is no way the LLM can see or access that document’s content.
You upload a document, this makes it possible to “Move into a workspace” or “embed” the document. Uploading takes your document and turns it into text - that’s it.
You “Move document to workspace”. This takes the text from step 2 and chunks it into more digestable sections. Those chunks are then sent to your embedder model and turned into a list of numbers, called a vector. This string of numbers is saved to your vector database and is fundamentally how RAG works. There is no guarantee that relevant text stays together during this step! This is an area of active research.
You type a question into the chatbox and press send.
Your question is then embedded just like your document text was.
The vector database then calculates the “nearest” chunk-vector. AnythingLLM filters any “low-score” text chunks (you can modify this). Each vector has the original text it was derived from attached to it. This is not a purely semantic process so the vector database would not “know what you mean”. It’s a mathematical process using the “Cosine Distance” formula. However, here is where the embedder model used and other AnythingLLM settings can make the most difference. Read more in the next section.
Whatever chunks deemed valid are then passed to the LLM as the original text. Those texts are then appended to the LLM is its “System message”. This context is inserted below your system prompt for that workspace.
The LLM uses the system prompt + context, your query, and history to answer the question as best as it can.
how can make retrieval better
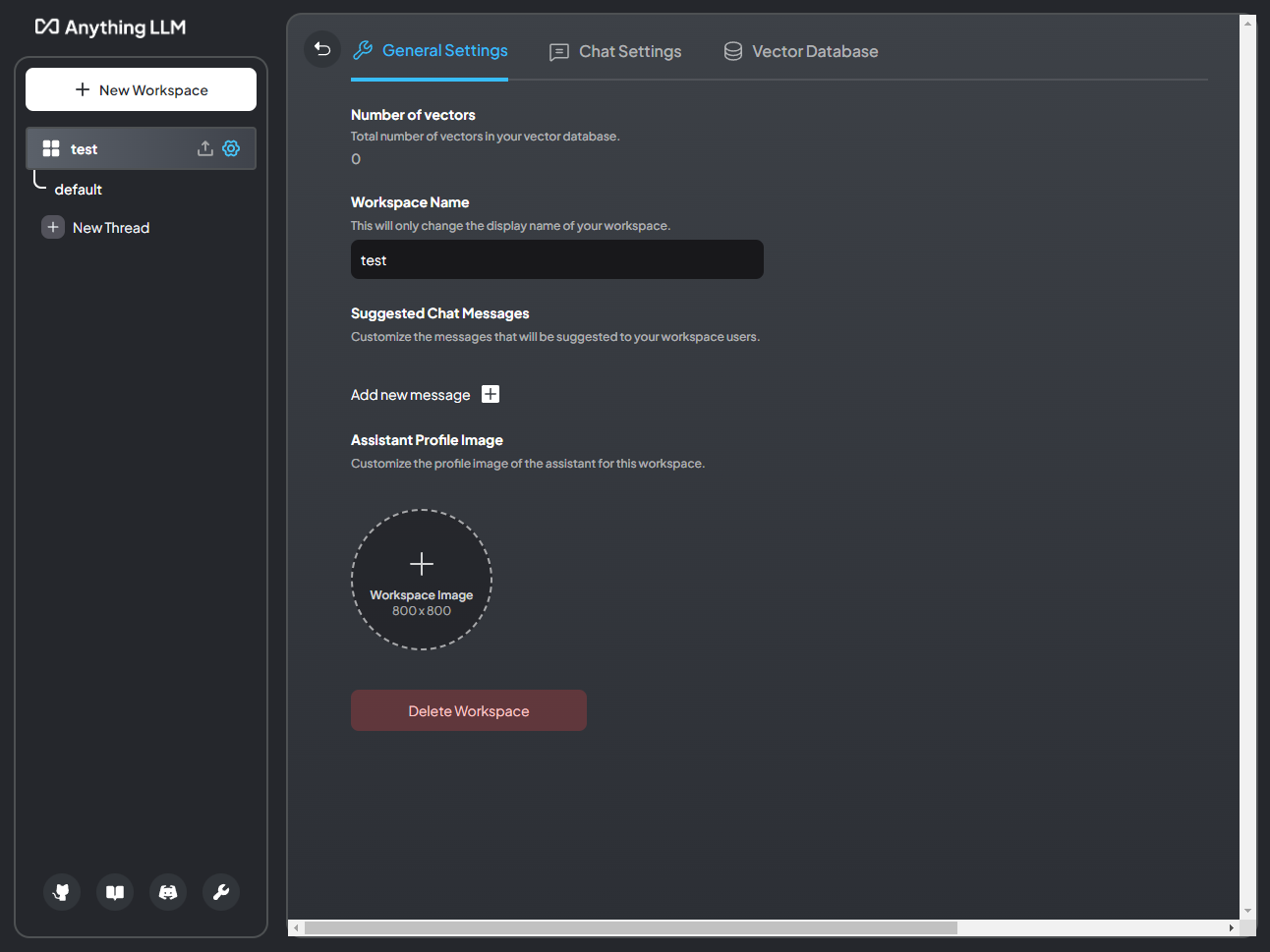
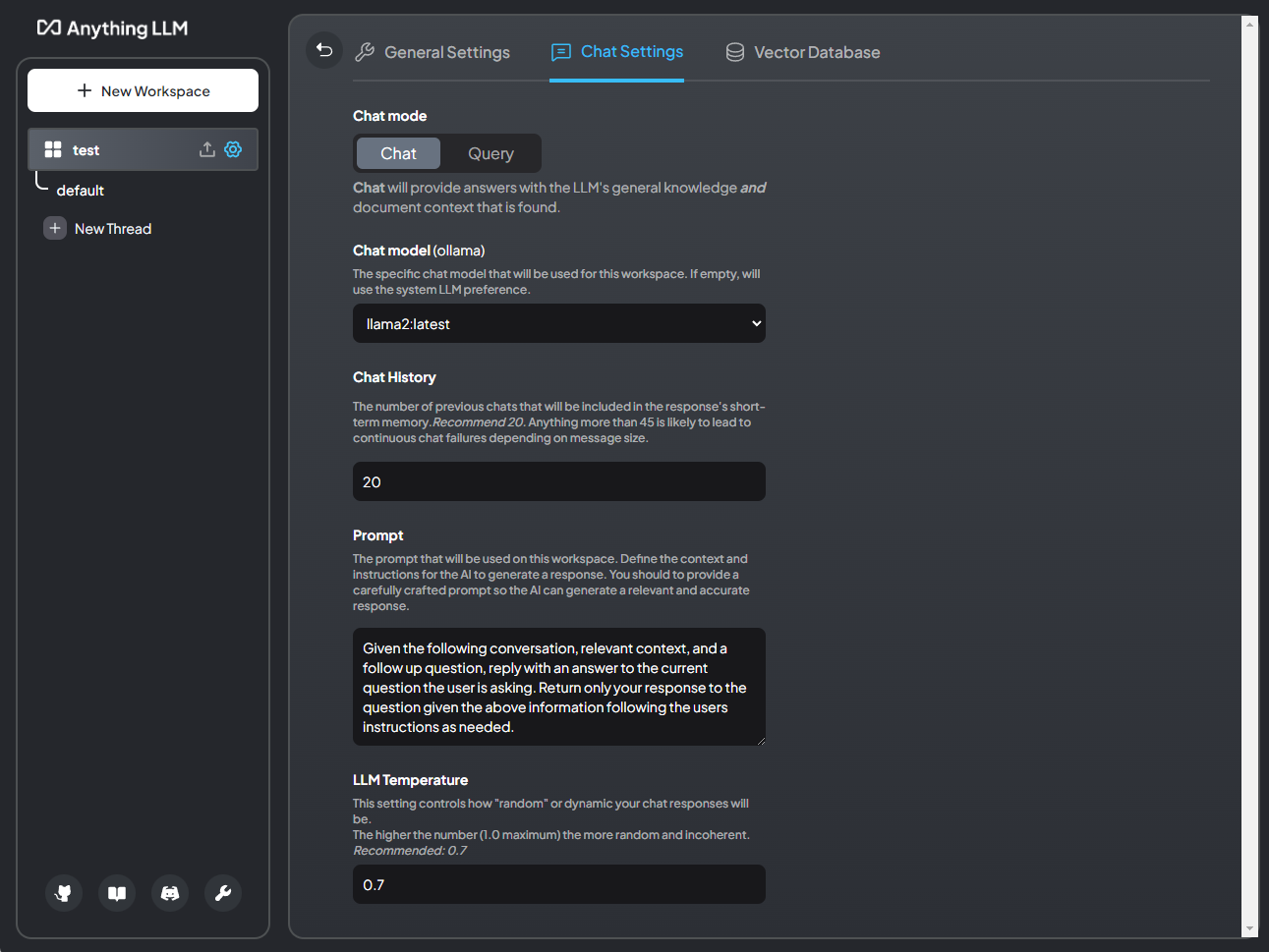
Chat Settings > Prompt
This is the system prompt for your workspace. This is the “rule set” your workspace will follow and how it will ultimately respond to queries. Here you can define it to respond in a certain programming language, maybe a specific language, or anything else. Just define it here.
Chat Settings > LLM Temperature
This determines how “inventive” the LLM is with responses. This varies from model to model. Know that the higher the number the more “random” a response will be. Lower is more short, terse, and more “factual”.
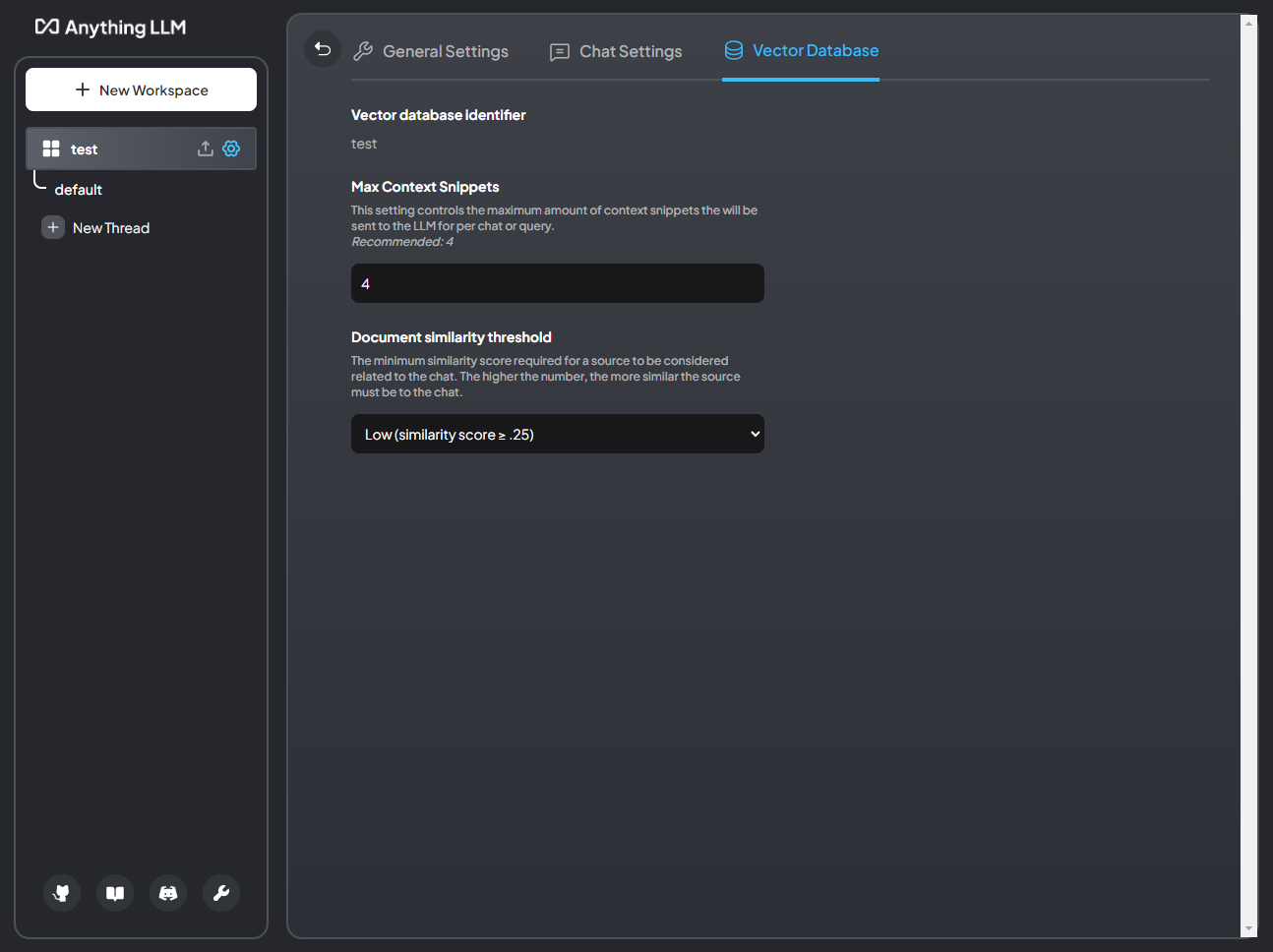
Vector Database Settings > Max Context Snippets
This is a very critical item during the “retrieval” part of RAG. This determines “How many relevant snippets of text do I want to send to the LLM”. Intuitively you may think “Well, I want all of them”, but that is not possible since there is an upper limit to how many tokens each model can process. This window, called the context window, is shared with the system prompt, context, query, and history.
AnythingLLM will trim data from the context if you are going to overflow the model - which will crash it. So it’s best to keep this value anywhere from 4-6 for the majority of models. If using a large-context model like Claude-3, you can go higher but beware that too much “noise” in the context may mislead the LLM in response generation.
Vector Database Settings > Document similarity threshold
This setting is likely the cause of the issue you are having! This property will filter out low-scoring vector chunks that are likely irrelevant to your query. Since this is based on mathematical values and not based on the true semantic similarity it is possible the text chunk that contains your answer was filtered out.
reference
https://github.com/Mintplex-Labs/anything-llm
https://github.com/Mintplex-Labs/anything-llm/blob/master/docker/HOW_TO_USE_DOCKER.md
https://docs.useanything.com/frequently-asked-questions/why-does-the-llm-not-use-my-documents
https://github.com/henrytanner52/all-MiniLM-L6-v2
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
本文标题:anything LLM with ollama - a private document chatbot
文章作者:Mr Bluyee
发布时间:2024-04-02
最后更新:2024-04-07
原始链接:https://www.mrbluyee.com/2024/04/02/anything-LLM-with-ollama-a-private-document-chatbot/
版权声明:The author owns the copyright, please indicate the source reproduced.